MRNet-Product2Vec: A Multi-task Recurrent Neural Network for Product Embeddings
2017년 9월에 나온 General한 Content-base Product embedding을 만드는 방법에 대한 아마존의 논문이다.
이 논문에서는 사용자의 View sequence, Purchase sequence와 같은 데이터를 사용하지 않고, 상품명, 상품설명, 카테고리와 같은 Product가 가진 고유한 정보들만을 사용해 임베딩을 만드는 방법을 다룬다.
이런 방법은 use behavior와 이 없기 때문에, 새로 등록된 상품이더라도 임베딩을 가질 수 있고, Cold starter problem을 해결하는데 쓰일 수 있다.
Introduction
간단히 상품명을 파싱하여 one hot encoding하고 이를 이용하여 product vector 즉 embedding을 만든다고 해보자.
이렇게 Product embedding을 만들면 각 벡터의 크기는 단어의 종류 갯수만큼이 될 것이고(high dimension) 벡터의 element값은 대부분 0일 것(sparse)이다. 이렇게 만든 피처를 카테고리분류나 추천과 같은 문제에 사용할 수도 있겠지만, 고차원 피처는 계산도 비효율적일 뿐더러 오버피팅을 야기할 가능성이 높다. 또, Nearest Neighbor search를 하기엔 단어만 다르면 완전 다른 디멘전에 있게 되니 별 의미도 없고, 딥러닝에 쓰자니 파라메터터수가 너무많아지는 문제가 있다. 이런 방법으로는 다른 문제에 범용적으로 쓸만한, 상품을 대변할만한 embedding을 얻는데엔 한계가 있다.
e-commerce에서 필요로 하는 유용한 product embedding이란 모름지기 1. 상품의 범용적인 시그널들을 담고 있으면서, 2. 다른 상품관련 ML모델에 사용할수 있어야 할 것이다.
Proposed Approach
이 논문에서는 MRNet-Product2Vector(Multi-task Recurrent Neural Network Product to Vector) 라 이름 붙인 방법을 제안한다.
구조를 간단히 요약하자면 다음과 같다.
- 상품명에 쓰인 단어들을 word2vec로 벡터화한다. (Gensim 으로 10번이상 등장한 단어들을 128차원 벡터로 만든다.)
- 이를 Bidirectional RNN의 인풋으로 삼고 RNN의 결과로 나온 두개의 벡터(Bidirectional 이니까 양쪽에서 두개)를 concat하여 길이 \(d\) 인 embedding을 만든다.
- 이 임베딩을 여러개의 분류, 회귀 문제를 푸는 모델의 인풋으로 삼는다. (총 15개의 task를 사용 한다.)
- 이러한 모델을 각각의 PG마다 학습시킨다. (총 23개 PG. 단계 2의 임베딩은 PG-specific embedding이라 할 수 있다.)
- 다른 PG에 해당하는 부분을 0으로 하여 임베딩을 확장하고, \(2d\) fully connected hidden layer를 가진 sparse autoencoder를 학습시킨다. 이때의 길이 \(2d\) 임베딩을 PG-agnostic embedding으로 한다.
Bidirectional Recurrent Neural Network
Bidirectional RNN로는 LSTM을 사용해 BPTT로 학습한다. 아래 그림처럼 word vector들은 순방향, 역방향으로 RNN의 인풋으로 들어가고, 그 결과를 이어붙여 embedding을 만든다
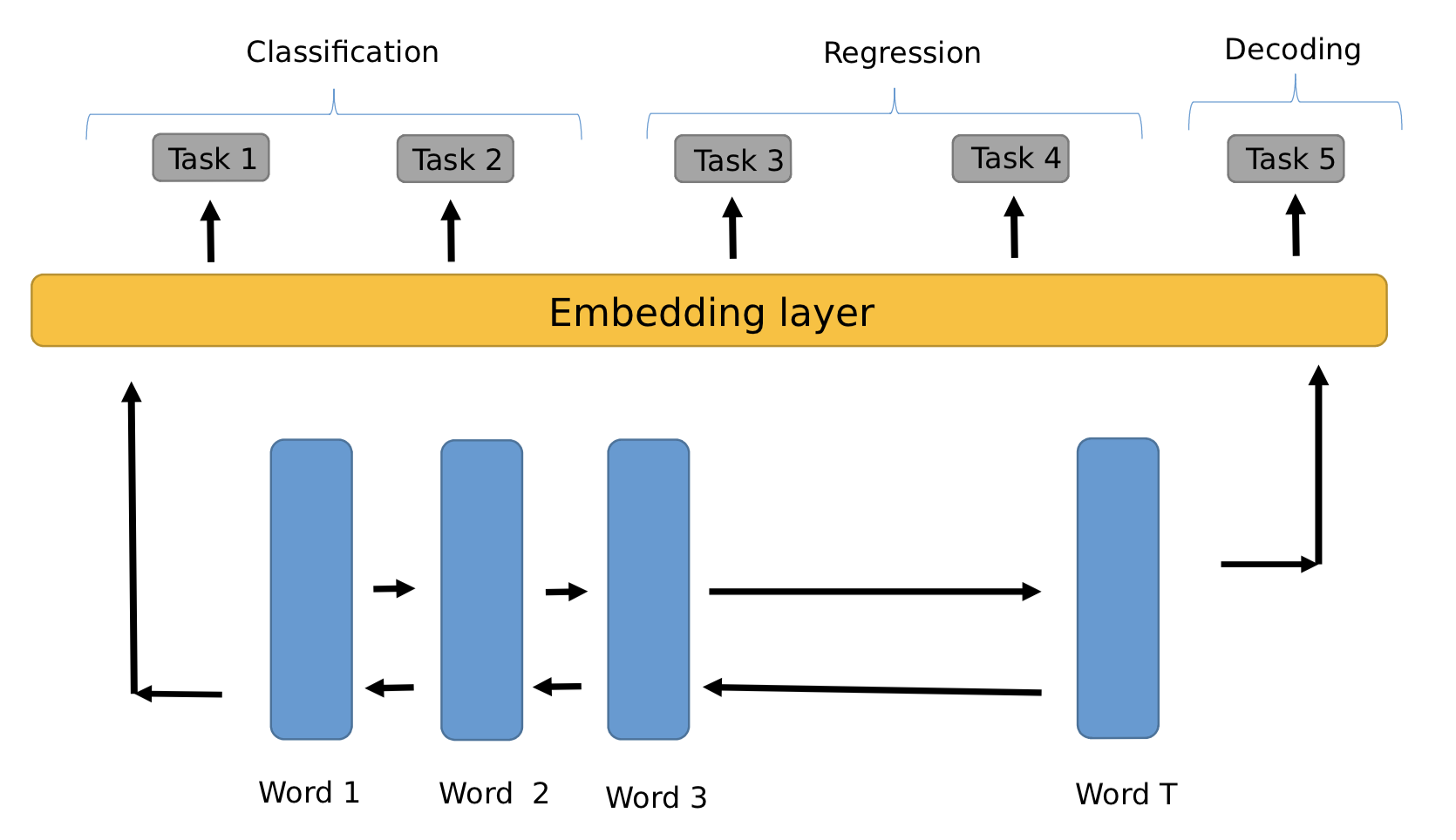
Fig.1: (a) MRNet-Product2Vec for PG-specific
좀 더 자세히 설명하자면, $t$ 번째 forward hidden layer 아웃풋을 $h^f_t$ 라 하고, backword hidden layer의 아웃풋을 $h^b_t$ 라 한다면, 이 둘은 아래와 같이 표현할 수 있고
[h^f_t = \phi(W^f x_t + U^f h^f_{t-1})
h^b_t = \phi(W^b x_t + U^b h^b_{t-1})
\text{where }U^f \text{ and } U^b \text{ are the recursive weight matrices.}
\phi \text{ is nonlinearity such as tanh or RELU.}]
우리가 사용할 최종 임베딩은 \(h_T = [h^f_T,h^b_T]\) 라 할 수 있다.
Sub tasks
상품의 속성에는 카테고리, 크기, 재료 등과 같이 시간에 따라 변하지 않는 속성들도 있고, 가격, 조회수, 리뷰 등과 같은 시간에 따라 변하는 속성들도 있다. 이러한 속성들을 모두 맞추도록 학습 태스크들을 구성하였지만, 이 태스크들이 프로덕트에 대한 모든 정보를 담지는 못하기 때문에, 아무래도 학습에 사용하지 않은 새로운 태스크의 경우 임베딩이 제 역할을 못할 가능성도 있다. 학습에 사용한 태스크의 목록은 아래와 같다.
Table 1: Tasks used to train MRNet-Product2Vec.
| Static | Dynamic | |
|---|---|---|
| Classification | Color, Size, Material, Subcategory, Item Type, Hazardous, Batteries, High Value, Target Gender | Offer, Review |
| Regression | Weight | Price, View Count |
| Decoding | TF-IDF representation (5000 dim.) |
Loss는 각 서브태스크의 로스의 합으로 정의한다. 분류문제의 경우, 임베딩에 softmax를 적용시켜 cross-entropy loss를 계산하고, 회귀문제는 스칼라 값으로 변환하여 squared loss를 구한다. 디코딩 태스크도 마찬가지로 5000차원으로 변환 후(\(o_n = W_nh_T + b_n\)) TF-IDF표현과 비교하여 squared loss를 계산한다.
하지만, 각 인풋마다 15개의 모든 태스크의 로스를 구하여 학습(Joint Optimization)을 시키지 않고, 랜덤하게 하나의 태스크를 골라 학습(Alternating Optimization)시키는 방법을 사용한다. 왜냐하면 태스크에 따라 label이 없을 수도 있기 때문이다. 다만, 이렇게 할 때엔 각 태스크를 균등하게 사용하여 학습이 편향되지 않도록 유의해야한다.
PG(Product Group) Agnostic Embeddings
사실 처음부터 PG에 상관없이 모델을 구성할 수도 있었을 것이다. 하지만 PG에 따라 가격분포, 재료, 크기 등의 속성이 워낙 다르기 때문에, PG 내부의 속성을 섬세하게 학습하지 못할 것이다. 따라서 총 23개의 PG마다 각각 PG-specific embedding을 학습시키고, sparse autoencoder 를 통해 PG-agnostic embedding을 따로 만든다.
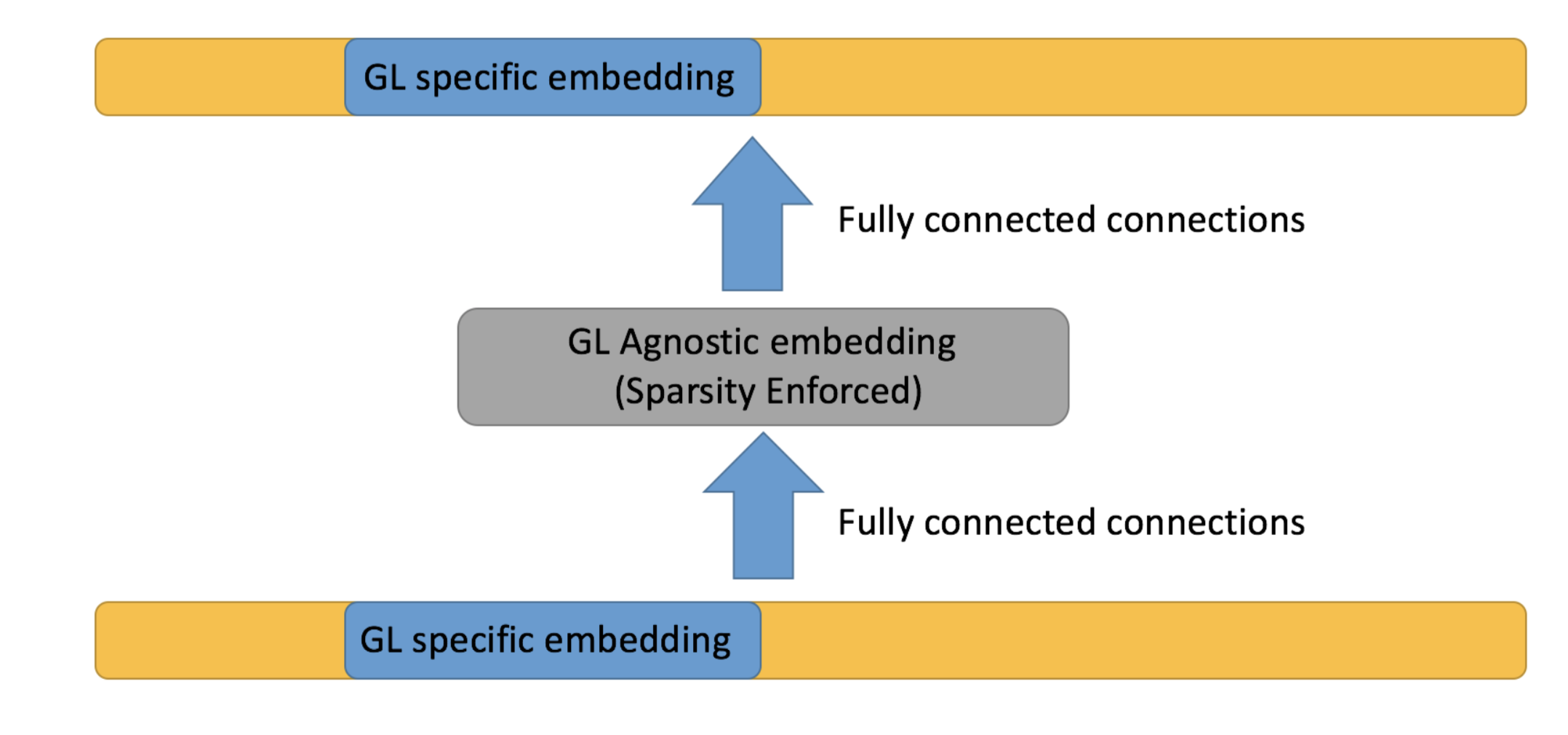
Fig.1: (b) Sparse Autoencoder for PG-agnostic embeddings
autoencoder는 PG-specific embedding을 확장한 벡터를 인풋으로 받는다.
[\text{Input} = [0,…,0,e^p_1, …,e^p_d,0,…,0] \text{ (length of } P*d \text{)}
P: \text{the number of PGs}
d: \text{the length of PG-specific embedding}]
중간에는 PG-specific embedding의 2배 길이의 layer를 두고, 이 \(2d\) 길이의 벡터를 PG-agnostic embedding으로 한다.
Experimental Results
각 PG당 최대 1M개의 학습데이터로 PG-specific model을 학습시킨다. Grid K520 GPU 하나를 사용했을때 한 에포크당 30분여가 걸린다.
PG-agnostic embedding을 만드는데에는 각 PG당 랜덤하게 500K개를 뽑아(총 11.5M개) 학습데이터로 사용한다. 한 에포크당 20분여가 걸린다.
학습에 사용한 것과 다른 5개의 분류 문제로 검증한다.
- Plugs: 플러그의 유무
- SIOC(Ship In its Own Container): 개별박스 포장 유무
- Ingestible: 식용가능 여부
- Browse Categories: PG 내의 서브카테고리로의 분류
여기 상품명이 겹치지 않더라도 유사한 상품을 잘 잡아내는지 확인하기 위한 검증도 한다.
- SIOC(unseen): 상품명에 겹치는 단어가 특정 threshold보다 적도록 학습데이터와 검증데이터를 나누어 SIOC를 수핸한다.
SIOC(unseen)는 AUC를 구하고, 위 네가지 분류문제에 대해서는 five-fold validatoin의 average AUC를 구한다.
Table 2: Results on five classification tasks. RF: Random Forest, LR: Logistic Regression. TF-IDF dim.: >10K, MRNet-Product2Vec dim.: 256 and 128. All numbers are relative w.r.t TF-IDF-LR.
| Task | MRNet-RF | MRNet-LR | TF-IDF-RF |
|---|---|---|---|
| Plugs | -2.8% | -9.72% | -2.8% |
| SIOC | -5.81% | -18.60% | -9.3% |
| Browse Categories | -16.67% | -26.38% | -25.0% |
| Ingestible | 0% | +2.15% | -11.8% |
| SIOC (unseen) | +10% | 0% | -3.33% |
결과가 나쁘게 보일수도 있는데, TF-IDF 3% 수준의 dimension임을 생각하면 꽤나 좋다.
Nearest Neighbor결과도 나쁘지 않다.

Fig. 2: Nearest neighbors computed using MRNet-Product2Vec for each query product (first column) (best viewed in electronic copy).
PG Agnostic MRNet-Product2Vec
글로벌 e-commerce에서는, 언어에 상관없이 상품에 대한 정보를 비교 검색해야하는 상황이 있을 수 있다. 예를들어 셀러 입장에서는 상품을 등록할 때 옆 나라에서는 유사한 어떤 제품이 어떻게 판매되고 있는지 알고 싶을 수 있고, 고객 입장에서는 내가 좋아하는 상품과 비슷한 상품이 다른 나라엔 어떤게 있나 찾아보고 싶을 수 있다. 또, 새로운 ML모델을 학습하는데 있어서는 언어에 따라 라벨 데이터가 없을 수도 있다.
따라서 product embedding은 언어에 상관이 없어야 한다. 여기서는 multimodal autoencoder를 변형하여 특정 언어로 학습한 product embedding을 common space로 옮겨본다.
영어로 학습한 길이 256인 p번째 프로덕트 임베딩을 \(x^{UK}_p\) 라 하고, 같은 상품에 대해 프랑스어로 학습한 길이 256 임베딩을 \(x^{FR}_p\) 라 할때 다음 세가지 데이터셋을 만들어 autoencoder를 학습시킨다.
- \[x_p = [x^{UK}_p, 0], \space y_p = [0,x^{FR}_p]\]
- \[x_p = [0,x^{FR}_p], \space y_p = [x^{UK}_p, 0]\]
- \[x_p = [x^{UK}_p, x^{FR}_p], \space y_p = [x^{UK}_p, x^{FR}_p]\]
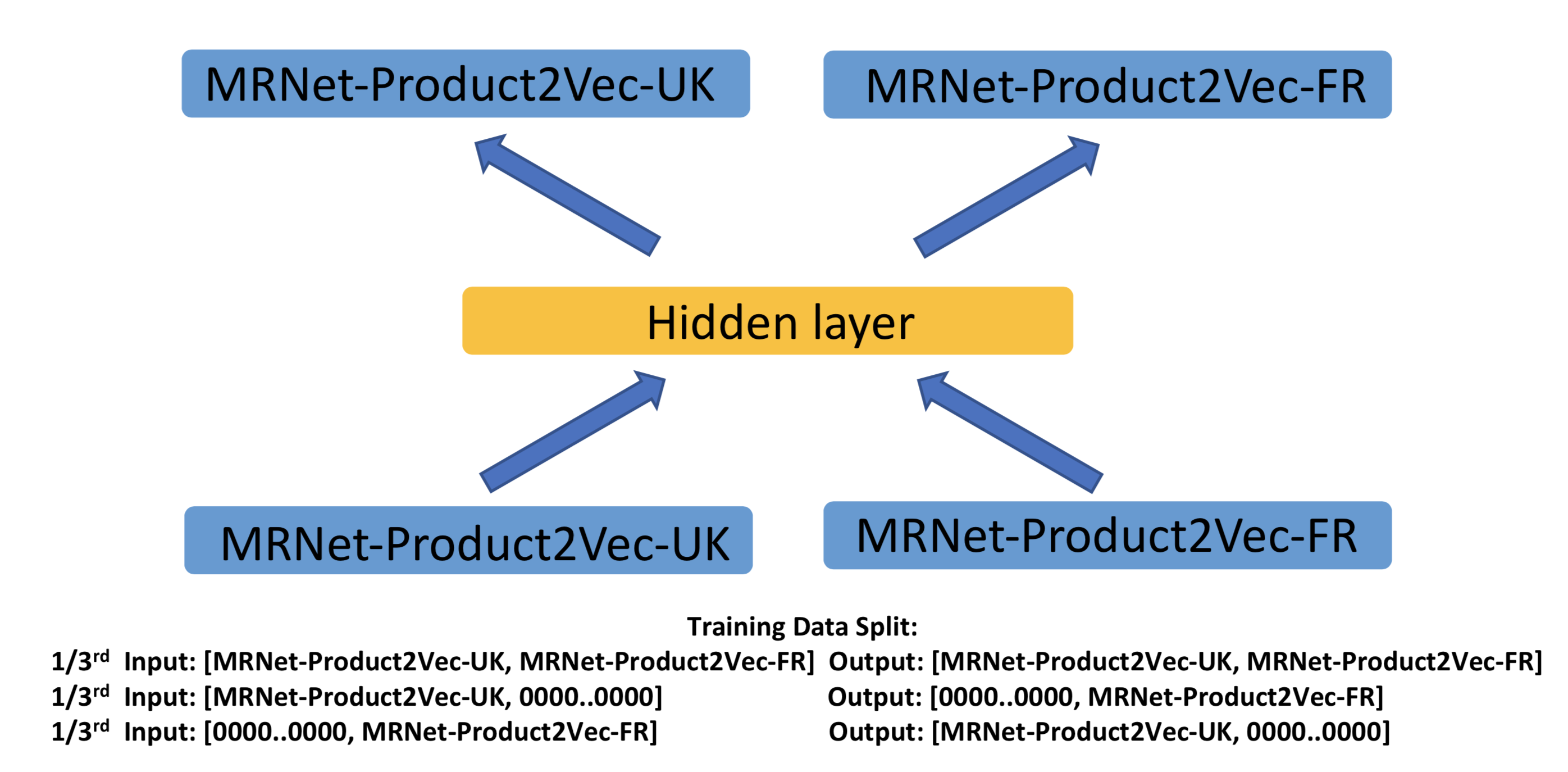
Fig. 3: Language Agnostic MRNet-Product2Vec (a) Architecture of Multimodal Autoencoder

Fig. 3: Language Agnostic MRNet-Product2Vec (b) Nearest neighbors from UK products
Discussion and Future Work
2B 개의 프로덕트에 대해서 학습시켜서 잘 사용하고 있다.
상품명만 사용하기 때문에 cold-starter 문제를 해결할 수 있다.
태스크는 원하면 더 추가할 수 있다는 장점이 있다.